대용량 데이터 처리에 따른 문제를 해결하기 위한 방법
데이터셋이 매우 크거나, 쿼리 처리량이 매우 높은 경우에는 단순히 복제하는 것만으로는 부족
> 큰 데이터베이스를 파티션이라는 작은 단위로 쪼개서 활용하는 방법이 제시
> 샤딩(shardIng)이라고도 표현
파티셔닝의 목적 > 확장성 > 확장되면서 점점 대용량의 데이터베이스가 되고, 그러한 환경에 맞게 프로세스를 처리할 필요성이 생김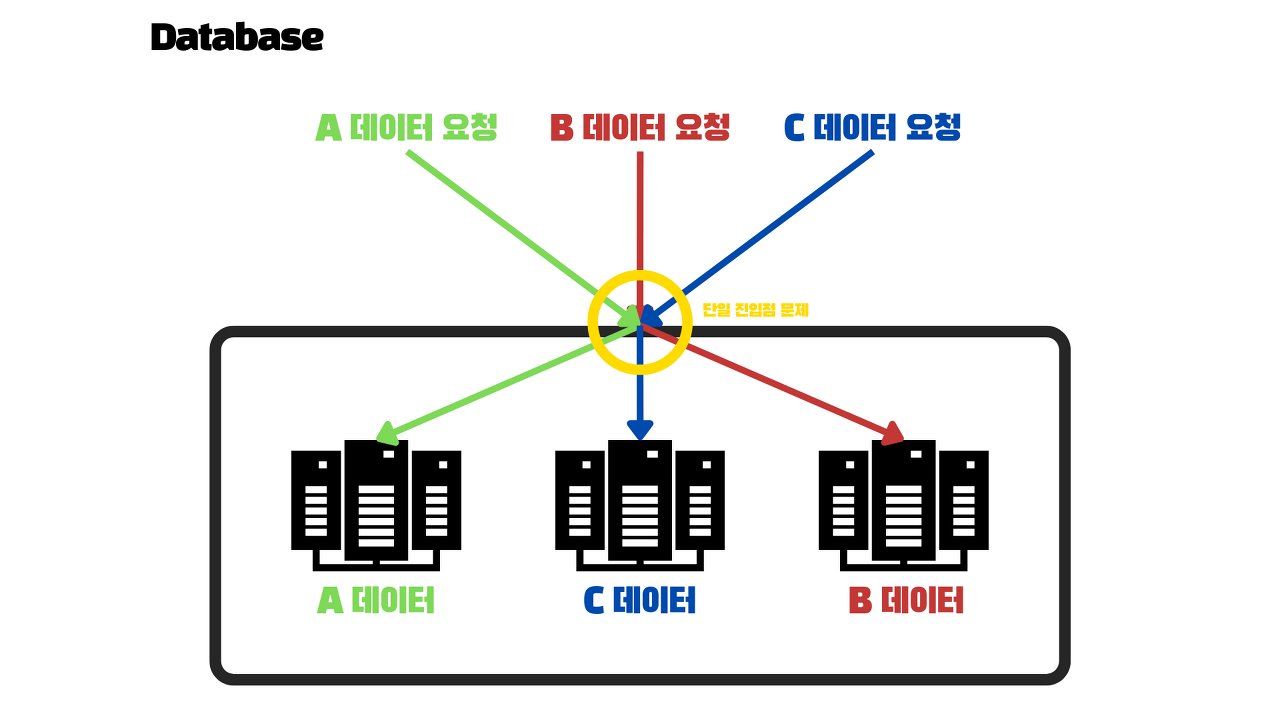
> 파티셔닝

but
> 데이터를 분산시켰음에도 불구하고, 특정 패턴을 가진 요청에 의해서 한 곳으로 요청이 쏠리는 현상(skewed)이 발생
> 파티셔닝의 효과가 떨어지게 되고, 극단적인 경우 모든 부하가 한 파티션에 몰려 4개 중 3개 노드가 사용되지 않는 것과 같은 효과
> 불균형하게 부하가 높아진 파티션을 핫스팟
> 파티션을 구성할 때는 데이터의 쿼리(질의) 부하를 노드 사이에 고르게 분산시킬 수 있도록 전략적으로 배치

1. 레코드를 할당할 노드를 무작위로 선택하는 것
> 데이터를 읽어내야 할 때는 특별한 기준으로 찾을 수 없기 때문에 성능저하
2. 키 범위를 기준으로 한 파티셔닝을 진행하는 것
> 백과사전처럼 데이터에 접근하기 위한 키를 일정한 기준(키이름에 대해서 a to z를 확인하거나 또는 저장 날짜를 기준으로 키를 분류)에 따라 배치해서 파티션을 구성
> 특정 접근 패턴이 핫스팟을 유발하는 경우가 여전히 존재
> 타임스탬프를 키로 사용해서 파티션 범위를 구성했다면, 하루치 데이터를 담당하는 특정 파티션에 쏠림 현상이 발생
3. 키의 해시값 기준 파티셔닝
> 범위 쿼리 효율성이 높은 키 범위 파티셔닝의 장점을 잃어버린다는 단점
'DevOps BootCamp > 데이터베이스' 카테고리의 다른 글
| 캐싱 (0) | 2023.03.29 |
|---|---|
| 캐싱 (0) | 2023.03.29 |
| 레플리카 (0) | 2023.03.29 |
| 낮은 검색 성능 - 인덱싱 (0) | 2023.03.29 |
| SQL - INSERT, UPDATE, DELETE (0) | 2023.03.29 |